Ich hatte gerade Lust mal wieder alle Folgen von Dragonball zu gucken. Leider gibt es das auf Netflix nicht, daher habe ich mir überlegt, wie ich das herunterladen könnte, wenn man über Google eine Seite finden könnte auf der es Dragonball gäbe.
Wenn ich eine Seite gefunden hätte, auf der man Dragonball streamen oder downloaden könnte, dann wäre es natürlich nervig auf alle 153 Seiten zu gehen, um dort die Links zum Video rauszusuchen um das dann zu JDownloader zu kopieren. Darum habe ich mir überlegt, wie ich mit node.js einen Crawler bauen könnte, der alle Videolinks sucht und in eine Datei schreibt.
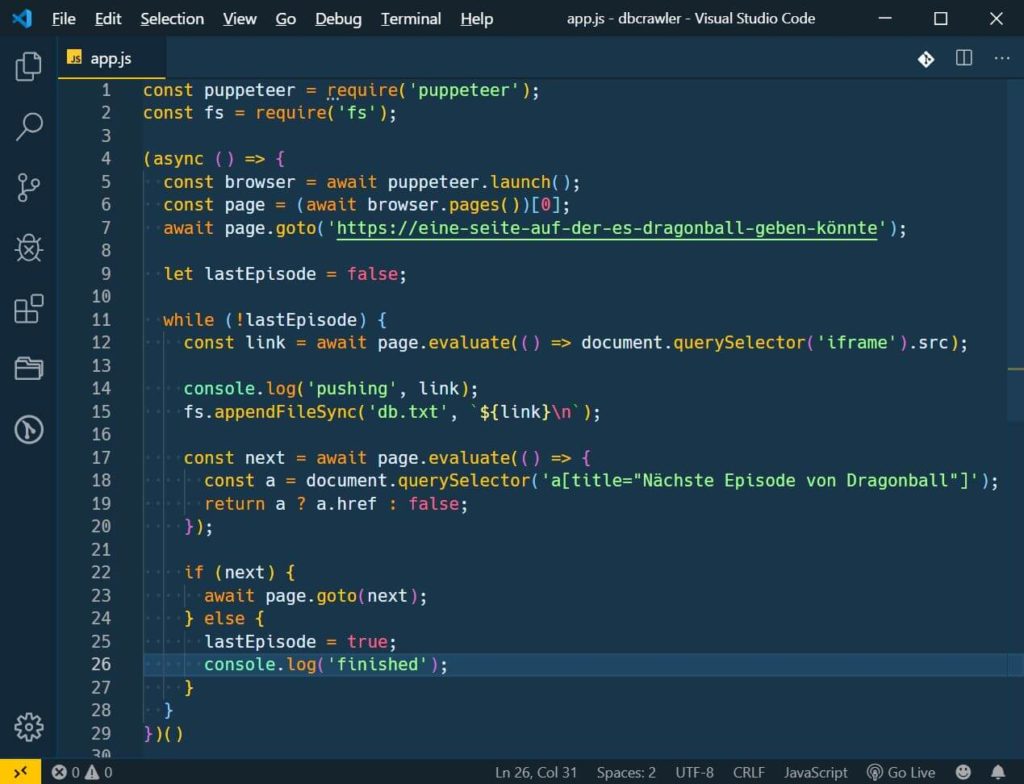
Mein erster Ansatz war Puppeteer. Mit Puppeteer startet node.js eine Instanz von Chrome und man kann per Code nachahmen, was man auf der Seite tun würde.
Der Code ist in einer IIFE, also in einer Funktion die sich selbst aufruft. Die benutze ich hier, damit ich async vor die Funktion schreiben kann und so mit await arbeiten kann. So lässt sich der Code besser von oben nach unten schreiben, sonst bräuchte ich immer wenn auf etwas gewartet werden soll ein Callback.
In dieser Funktion starte ich zunächst puppeteer (also quasi Chrome) und schnappe mir den ersten Tab mit (await browser.pages())[0]. In dem Tab gehe ich auf die Seite, auf der man Dragon ball finden könnte.
Ich will immer wieder einen Link suchen, daher habe ich mich hier für eine while Schleife entschieden. Diese wird unterbrochen, wenn es die letzte Episode ist. Ich setze eine Variable lastEpisode erst mal auf false und überlege mir später, woher ich weiß, dass es die letzte ist.
Mit puppeteer kann man page.evaluate() benutzen. Das ist eine coole Funktion, mit der man Javascript in der virtuellen Chrome Konsole ausführen kann und von dort Werte zurückgeben. Ich will nur den src vom Iframe in dem das Video ist, daher reicht hier ein einfacher querySelector.
Mit fs.appenFileSync kann ich bei einer Datei eine Textzeile anhängen. Das ist in dem Fall der src vom iframe.
Um die nächste Folge zu finden suche ich wieder mit evaluate nach dem Link dort hin. Falls es den gibt, soll mein Tab auf diese Seite gehen und wenn nicht wird lastEpisode auf false gesetzt. Dadurch wird die while schleife in der nächsten Runde unterbrochen.
Am Ende hat man ein Textdokument mit allen Links, die man in JDownloader kopieren könnte.
Nachdem ich es mit Puppeteer gelöst habe, hatte ich noch Lust es einfach interessehalber noch ohne headless Browser zu lösen. Zum einen weil ich fand, dass es eh ein relativ einfaches und reduzierbares Problem ist und zum anderen, weil es mit dem Browser ein bisschen langsam ist.
Beim nächsten Ansatz habe ich deshalb anstatt Puppeteer zu verwenden direkt den http Stack von node gewählt.
Ich habe wieder eine IIFE, diesmal aber nicht weil ich asynchron arbeiten will, sondern weil ich Rekursiv arbeite, um die while Schleife vermeiden zu können. So kann ich die Funktion sofort mit der url zu der Seite aufrufen und die gleiche Funktion später mit den URLs zu den weiteren Folgen benutzen.
In der Funktion rufe ich per http.get den rohen body von der Seite auf mit res.setEncoding, res.on data und res.on end bastel ich die Seite zusammen. Das habe ich auch nur aus der Dokumentation zusammenkopiert.
In res.on end konnte ich mir den gesamten Textbody, also den HTML Code der Seite ausgeben lassen. Hier habe ich jetzt aber keinen Zugriff auf das DOM, so wie in puppeteer und deshalb suche ich mir die Links per Regex.
Wenn ich Regex benutzen will, dann gehe ich immer auf Seiten wie https://regex101.com/. Da kann man einen Text rein kopieren und am Regex herumprobieren. Direkt dort werden einem auch noch mal die verschiedenen Sachen erklärt, die man mit Regex so anstellen kann.
body.match(/iframe.*src=”(.*?)”.*iframe/)[1];
suche nach einem text, der mit iframe anfängt und aufhört und dadrin sein src=”irgendwas” hat. Mit den Klammern und der [1] komme ich direkt an eine Teilmenge vom Gefunden Text.
/”(.*?)”.*Nächste Folge/
Hier suche ich nicht mal nach <a>, ich weiß, dass der Text “Nächste Folge” nur einmal auf der Seite vorkommen würde und dass der href immer in den ersten Anführungszeichen davor wäre.
Den src vom iframe kann ich wieder in meine Datei schreiben zum später kopieren. Wenn es einen Text “Nächste Folge” gab, dann führe ich die Funktion noch mal aus mit dem neuen Link und wenn nicht, dann logge ich zur Info nur noch, dass es Fertig ist.
Ich fand es ganz spannend das gleiche Problem auf zwei sehr unterschiedliche Arten anzugehen. Nicht nur der Unterschied Puppeteer / http, sondern auch Schleife / Rekursion ist hier eine nette Spielerei.
Weil ich mit dem Problem so viel Spaß hatte, habe ich auch noch eine Version mit Powershell gemacht. Den Code kommentiere ich hier jetzt nicht, das ist eigentlich das gleiche wie die zweite Version mit Node. Aber mit Powershell. Also kann man es ohne Umwege auf jedem Windows PC benutzen.